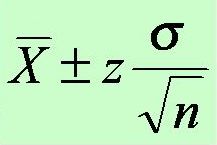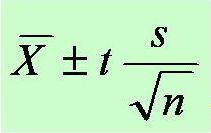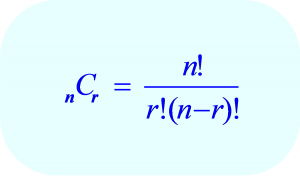1. Basic arithmetic and algebra: When coming into statistics, it can be really helpful to remember the order of arithmetic (Parenthesis, exponents, Multiplication and Division, Addition and Subtraction). You also will be using a little bit of algebra every once in a while, so make sure you brush up on the rules before you jump into stats.
2. Meaning of Greek symbols in math: Looking at statistical formulas might seem a little overwhelming the first time, because they tend to be filled with a lot of Greek letters and symbols. To make that first day of statistical formulas easier, try looking up the meanings of the different symbols being used and write them down.
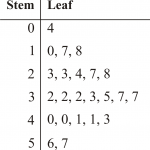
3. How to find mean, median, and mode: Sometimes, it can be easy to mix up these three when referring to “average.” The differences are important to remember, so if you’re not sure how to find each of these, it might be helpful to look at our FAQ page to find the answer. You’ll definitely need to know for later on in your stats class.
4. Basic (REALLY basic) computer skills: In most statistic classes, you will have to use an online program (such as SPSS or Excel) to interpret the data or run different statistical tests. You don’t have to know how to run them beforehand (that’s what the classes are for!), but it does help to just have a basic understanding of how to work a computer. Also, make sure to take notes in class on the steps needed for running tests, because it might get easy to mix them up later on in the semester.
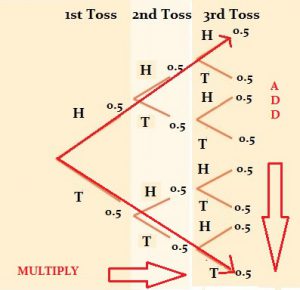
5. Basic probability: In some statistic classes, you might be required to solve problems about probability. It would be helpful to have some understanding of how you find probability and what it is in a simple way.
6. Ability to interpret word problems: Statistics classes LOVE to use word problems and different scenarios to present information to you. Sometimes it can be difficult to weed through all of the random facts to find what the actual problem is. Before you start working on a problem, try to make sure you have a clear understanding of what the question is asking; that way, you won’t waste time solving a problem you weren’t even asked to solve.
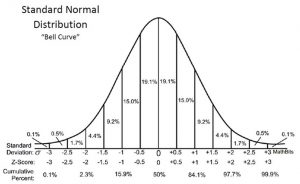
7. Understanding “variance” and “spread”: Variance and spread are terms that you will hear a lot in statistics. They basically refer to how close or far apart the numbers are in the data set (for example, if all of the numbers fall between 1 and 5, this data set would have a smaller spread than a data set with numbers ranging from 1 to 15). Having an understanding of these terms will be helpful when studying statistics.
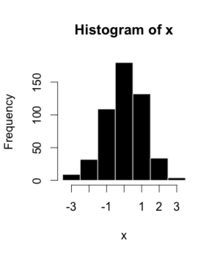
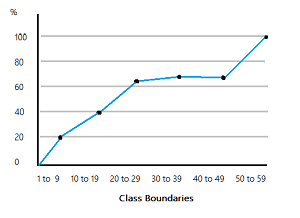
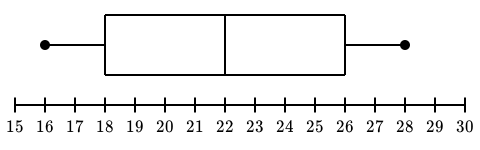
8. Interpreting graphs: Statisticians often show their information in the forms of graphs. It is helpful to know what the graphs mean and how to interpret them. Not only does this help you understand the data given, but it also helps you know how to present your own data, should you need to make your own graphs someday.
9. How to ask the right questions: In research as well as in statistics, it is extremely helpful to know how to ask the right questions. When you begin to ask questions like, “How does X connect to Y?” or “What happens to Y when it is influenced by X?” it becomes easier to understand the questions given in class or in homework assignments.
10. Know that you can learn this! This is probably the most important point in this whole list. Coming into a statistics class with confidence is crucial to the learning process. Once you realize that you can learn the information, you can push past mistakes or information that confuses you, because you know that you can grow in the process. So when you get that homework assignment that seems impossible, or your teacher is explaining material that just doesn’t make sense, don’t lose hope! Statistics is learnable.